Data Availability in Blockchains – Exploring the Data Availability Layer
Blockchain, Data Availability Layer, What is Data Availability in Blockchains

Blockchain networks have several central functions, including executing transactions, ordering transactions, and guaranteeing the availability of block data. This article will focus on the latter, which the industry generally refers to as ”data availability”. Data availability is essential for a blockchain network’s security and decentralized scalability. However, what exactly is data availability in blockchains, and what is a data availability layer? Follow along as we address these questions and examine the intricacies of data availability in further detail throughout this article!
What is Data Availability in Blockchains?
Trustlessness is a central characteristic of most decentralized blockchain networks. In a trustless system, participants do not need to rely on a third party or trust one another (”don’t trust, verify”). To reduce the need for trust assumptions, networks like Ethereum enforce clear rules regarding what is known as ”data availability”. But what does data availability mean in a blockchain context?

Data availability is the guarantee that block proposers publish all transaction data of a block, along with making this data available to all network participants. In essence, it refers to all nodes’ ability to access and download all the data contained within the various blocks of a network.
So, why is data availability important for blockchain networks?
Why is Data Availability Important?
To better understand what data availability is and why it is important, let us start by briefly breaking down the architecture of blocks. Blocks generally consist of the following two main components:
Block Header – The block header contains information (metadata) about the block. This includes the block number, block hash, timestamp, etc.
Block Body – The block body consists of all the transaction data processed as part of the block in question.

Whenever a new block is proposed, the proposer needs to publish the entirety of a block’s data, including both the header and the body. From there, the nodes participating in consensus can download the data and re-execute transactions to confirm the block’s validity. Without nodes verifying the data, block proposers can get away with including malicious transactions.
Consequently, if block proposers refuse to publish the block body (containing the transaction data), nodes cannot verify the proposed block’s integrity. So, to avoid this issue, blockchain networks need to ensure that the block proposer makes a block’s entire data available to the rest of the network. This is achieved by enforcing data availability rules.
To further explore why data availability is important, let us get more specific and discuss how this concept contributes to blockchain security and decentralized scalability!
Blockchain Security
Data availability is essential to a blockchain network’s security. Without data availability, so-called ”data withholding attacks” would be common practice. These attacks occur when block producers publish blocks without sharing the transaction data that compromises the block in question.

The visibility of block data is critical because other peers in the network, such as light clients, rely on the network’s full nodes to verify the state of the network. Unlike full nodes, light nodes only check the block headers and do not download the block body. Consequently, the rules surrounding data availability are how full nodes can validate blocks and prevent fraudulent on-chain behavior.
Decentralized Scalability
Due to the inherent constraints of a monolithic blockchain architecture, data availability is essential in achieving decentralized scalability. Blockchain networks like Ethereum rely on layer-2 (L2) scaling solutions – such as rollups – to increase latency and throughput. This is accomplished by processing transactions away from Ethereum’s main execution layer.

However, to securely leverage layer-2 (L2) scaling solutions, the network needs mechanisms for verifying the validity of the off-chain transactions, which is where data availability comes into the picture!
Now, with a better understanding of why data availability is critical, let’s look at some of this mechanism’s most significant challenges!
Challenges of Data Availability – The Data Availability Problem
As we discovered in the previous section, data availability is essential to most blockchain networks. Unfortunately, keeping data available can be somewhat challenging and does not come without problems. So, what are some of the common challenges associated with data availability?
There are two key data availability challenges we will examine further:
Requiring blockchain nodes to download and verify data lowers throughput.
Using on-chain storage for an increasingly large amount of data inherently limits the number of entities that can run nodes.
Monolithic blockchain networks ensure data availability by storing state data on several nodes so that network participants needing this information can request it from another peer. Unfortunately, this implementation of data availability includes numerous problems.
Requiring a large number of nodes to download, store, and verify the same data significantly reduces throughput for blockchains. This is why the processing speed of blockchain networks such as Ethereum and Bitcoin is relatively low. Storing data on-chain also leads to a significant increase in the size of the blockchain networks. This exponentially increases hardware requirements for so-called full nodes that need to accumulate increased amounts of states.
The need for higher storage capacity is even more problematic with the rising costs of high-spec hardware. This lowers the number of individuals running nodes, contributing directly to a higher risk of centralization.
Exploring the Data Availability Layer in Blockchain
In a blockchain, the data availability layer refers to the system storing and providing consensus on the availability of blockchain data. There are two types of blockchain availability layers: the on-chain data availability layer and the off-chain data availability layer. So, what exactly does this mean?

On-Chain Data Availability Layer – The most common solution for solving data availability is to force producers to publish all the transaction data on-chain and have the validating nodes download it. On-chain data availability is a common feature of monolithic chains. Moreover, monolithic blockchains are networks managing data availability, transaction execution, and consensus on one single layer.
Utilizing an on-chain data availability layer does, unfortunately, result in scalability bottlenecks. This occurs because monolithic blockchain nodes need to download all blocks and replay the same transactions. In addition, an on-chain data availability layer ensures high data availability; however, it also limits decentralization.
Off-Chain Data Availability Layer – Off-chain data availability layers move data storage of the blockchain network. This means that block producers do not need to publish the transaction data but rather provide a cryptographic commitment to prove its availability. This is the method used by modular blockchains, where the network offloads, for instance, data availability and manages some tasks like consensus and transaction execution.
While off-chain data availability layers drastically increase efficiency, they can have a negative impact on trustlessness, decentralization, and security. For example, malicious block producers can act in bad faith and cripple attempts to challenge transactions by deliberately withholding state data.
So, how can we solve these issues with the various data availability layers?
Different Data Availability Layer Solutions
Data availability problems concern the ability to verify the availability of transaction data for a newly proposed block. To solve this issue, we require some mechanisms that can guarantee the availability of transaction data. Down below, you can find three potential solutions:
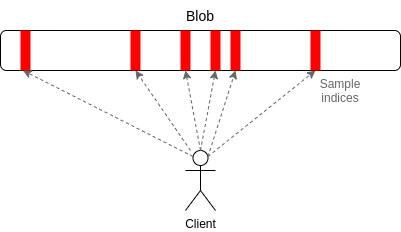
Data Availability Sampling – Data availability sampling, or DAS, is a cryptographic mechanism for guaranteeing data availability. This mechanism allows blockchain nodes to verify that data is available without downloading the entirety of a block.
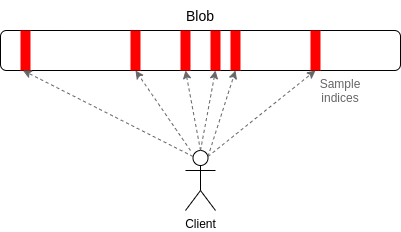
In this system, nodes only sample small, random pieces of a block over several rounds to verify data availability. As many nodes are sampling different parts of a block simultaneously, the availability can be verified with high statistical certainty.
Data Availability Proofs – While a DAS mechanism statistically guarantees a block’s data availability, malicious nodes can still hide data. DAS systems only ensure that most data is available, not the entire block.
So, to solve this issue, it is possible to combine DAS with ”erasure coding” to create data availability proofs. Erasure coding is a method that allows networks to double datasets by adding redundant pieces known as ”erasure codes”. If the original data is lost, it is possible to use erasure codes to reconstruct the original information.
Data Availability Committees – A data availability committee (DAC) is a group of permissioned entities tasked with keeping copies of blockchain data offline. A DAC often consists of trusted members appointed to this specific role. Furthermore, block producers must send transaction data to DAC members when performing state transitions. This eliminates the risk of centralization as the DAC can make the information available to users.
Summary – Exploring the Data Availability Layer
In this article, you got to learn about the intricacies of data availability in blockchains. In doing so, we taught you that data availability refers to a blockchain node’s ability to access and download block data. Along with exploring the ins and outs of data availability, you also learned about the importance of enforcing data availability rules. Lastly, the article covered some common data availability problems